Intro
OpenMP是共享内存体系结构上的一个基于多线程的并行编程模型,适用于SMP共享内存多处理系统和多核处理器体系结构。支持C/C++/Fortran.
OpenMP由三部分组成
- 编译器指令(compiler directives)
- 运行时库程序(runtime routines)
- 环境变量(environment variables)
OpenMP’s machine model
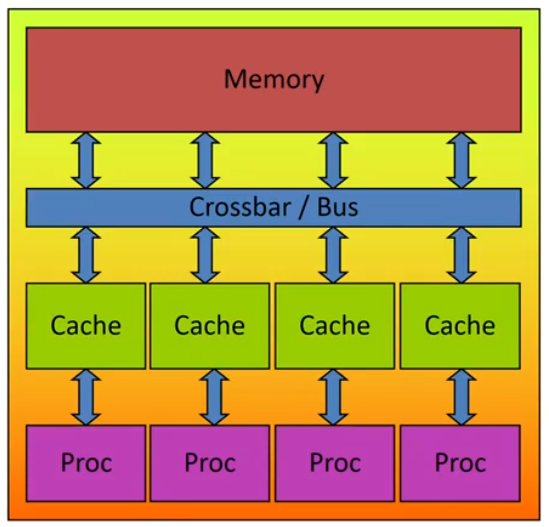
OpenMP: Shared-Memory Parallel Programming Model
All processors/cores access a shared main memory.
Parallelization in OpemMP employs multiple threads.
OpenMP’s memory model
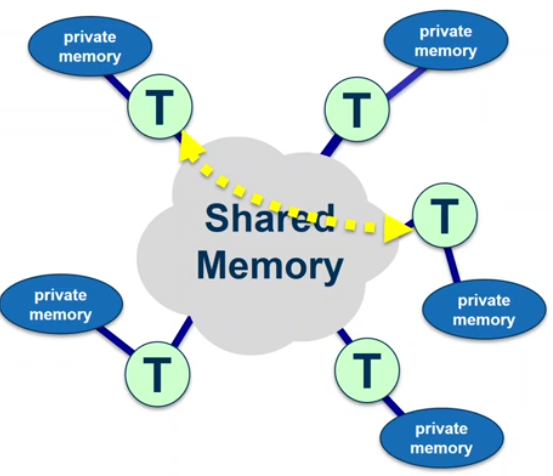
- All threads have access to the same, globally shared memory.
- Data in private memory is only accessible by the thread owning the memory.
- No other thread sees the changes in private memory.
- Data Transfer is through shared memory and 100% transparent to the application.
OpenMP’s Execution model
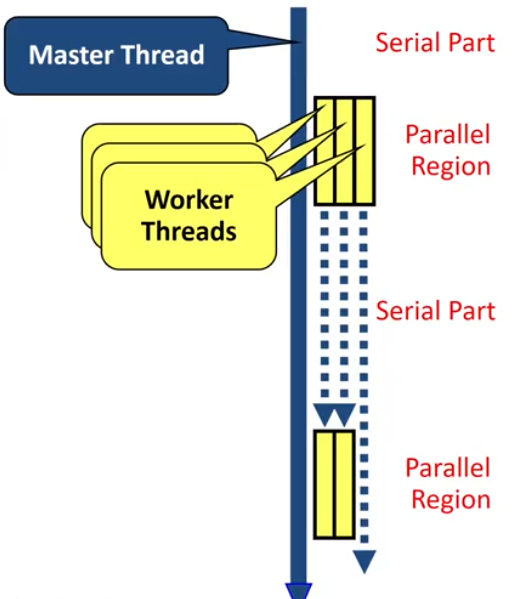
OpenMP programs starts with just one thread: The Master Thread. It’s used as an Initial Thread.
- Worker threads are spawned at Paralllel Region, together with the Master they form the team of threads.
- In between Parallel Regions the Worker Threads are put to sleep. The OpenMP Runtime takes care of all thead management work.
Concept: fork-join model. The fundamental model behind OpenMP. It Allows for an incremental parallelization.
Parallel Region and Structured Blocks
The parallelism has to be expressed explictly
1
2
3
4
5
6
#pragma omp parallel
{
...
structured block
...
}
structured block
- exactly one entry point at the top
- exactly one exit point at the bottom
- Branching in or out is not allowed
- terminating the program is allowed(abort/exit)
specification if num of threads
- Environment variable:
1
export OMP_NUM_THREADS=...
via num_threads clause
add
num_threadsto the parallel construct
Worksharing
- Loop construct
- Sections/Section construct
- Single Construct
- Task Construct
If only the parallel construct is used, each thread executes the structured block.
Program speedup: Worksharing
OpenMP’s most common Worksharing construct: for
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
int i;
// Sequential code
for (i = 0; i < N; ++i) {
a[i] = b[i] + c[i];
}
// OpenMP parallel region
#pragma omp parallel
{
int id, i, Nthrds, istart, iend;
id = omp_get_thread_num();
Nthrds = omp_get_num_threads();
istart = id * N / Nthrds;
iend = (id+1) * N / Nthrds;
if (id == Nthrds - 1) {
iend = N;
}
for (i = istart; i < iend; ++i) {
a[i] = b[i] + c[i];
}
}
// OpenMp parallel region and
// a worksharing for construct
#pragma omp parallel
#pragma omp for
for (i = 0; i < N; ++i) {
a[i] = b[i] + c[i];
}
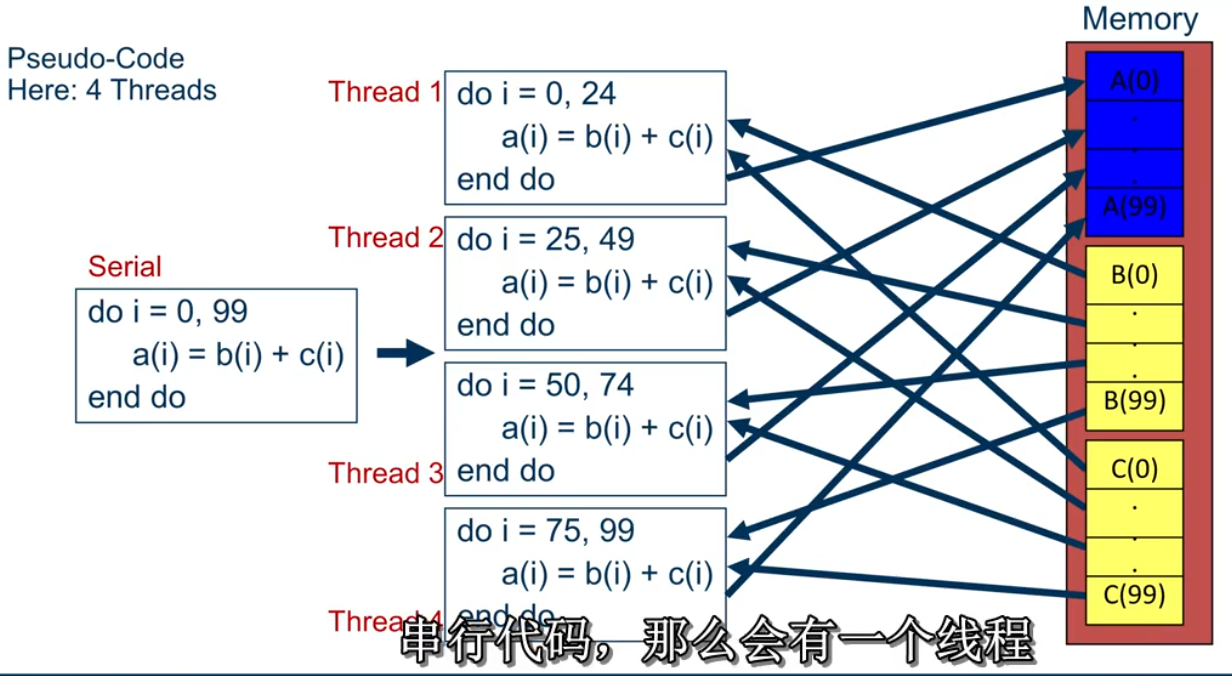
distrubution of loop iterations over all threads in a Team.
Scheduling of the distrubution can be influenced.
Loops often account for most of a program’s runtime.
influencing the for loop scheduling
for-construct: OpenMP allows to influence how the iterations are scheduled among the threads of the team, via the schedule clause.
- schedule(static [, chunk]): Iteration space divided into blocks of chunk size, blocks are assigned to threads in a round-robin fasion. If chunk is not specified: #threads blocks.
- schedule(dynamic [, chunk]): Iteration space divided into blocks of chunk(not specified: 1) size, blocks are scheduled to threads in the order in which threads finish previous blocks.
- schedule(guided [, chunk]):Similar to dynamic, but block size starts with implementation-defined value, then is decreased exponentially down to chunk.
- schedule(runtime): Schedule and chunk size taken from the OMP_SCHEDULE environment variable(or the runtime library)
- schedule(auto) schedule is left up to the runtime to choose(does not have to be any of the above)
When to use the schedule clause
static
Pre-determined and predictable by the programmer. Least work at runtime, Scheduling done at compile time.
dynamic
Unpredictable, highly variable work per iteration. Most work at runtime. Complex scheduling logic used at runtime.
Default on most implementation is shcedule(static).
Critical Region
A Critical Region is executed by all threads, but by only one thread simultaneously(Mutual Exclusion)
1
2
3
4
5
6
int i, s= 0;
#pragma omp parallel for
for (i = 0; i < 100; ++i) {
#pragma omp critical
{ s = s + a[i]; }
}
The Barrier Construct
Threads wait until all the threads of the current Team have reached the barrier.
1
#pragma omp barrier
All worksharing constructs contain an implict barrier at the end.
The Single Construct
1
2
#pragma omp single [clause]
... structured block ...
The single construct specifies that the enclosed structured block is executed by only one thread of them.(It’s up to the runtime which thread that is)
Useful for:
- I/O
- Memory allocation and deallocation, etc.
The master Construct
1
2
#pragma omp master[clause]
... structured block ...
The master construct specifies that the enclosed structured block is executed only by the master thread of team.
Note: The master construct is no worksharing construct ans does not contain an implicit barrier at the end.
The sections/section Construct
1
2
3
4
5
6
7
8
9
10
11
12
#pragma omp parallel
{
#pragma omp sections
{
#pragma omp section
x_calculation();
#pragma omp section
y_calculation();
#pragma omp section
z_calculation();
}
}
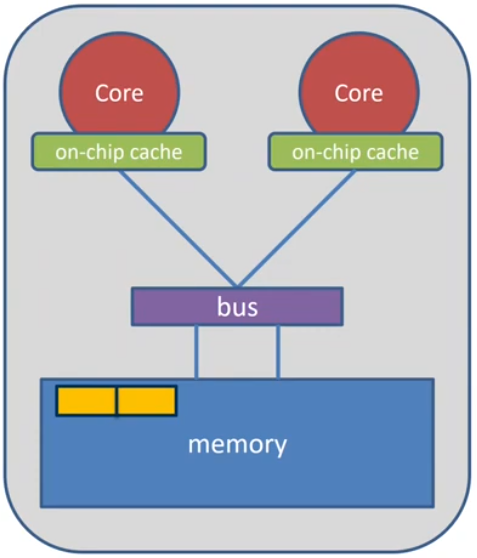
False Sharing
Caches
CPU is fast
- Order of 3.0 GHz
Caches
- Fast, but expensive
- small, order of MB
Memory is low
- Order of 0.3 GHz
- Large, order of GB
Thus, a good utilization if caches is crutial for good performance of HPC applications!
Data in Caches
when data is used, it is copied into caches.
The hardware always copies chunks into the cache, so called cache-lines.
This is useful, when:
- the data isc used frequently(temporal locality)
- consecutive data is used which is on the same cache-line(spatial locality)
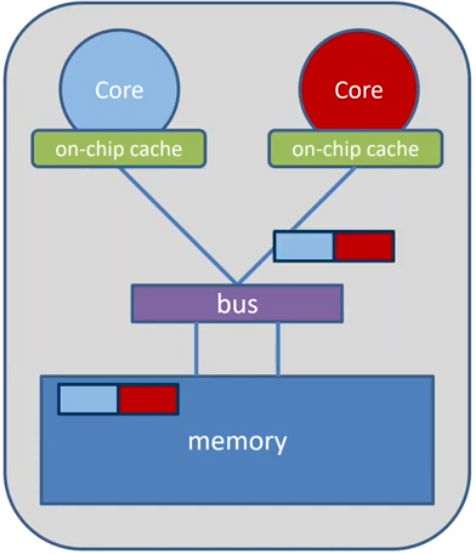
False Sharing
False Sharing occurs when
- different threads use elements of the same cache-line
- one of the threads writes to the cache-line each update will cause the cache lines to “slosh back and forth” between threads.
As a result, the cache line is moved between the threads, although there is no real data dependency.
Note: False sharing is a performance problem, not a correctness issue.
1
2
3
4
5
6
7
8
9
10
11
12
13
double s_priv[nthreads];
#pragma omp parallel num_threads(nthreads)
{
int t = omp_get_thread_num();
#pragame omp for
for (int i = 0; i < 99; ++i) {
s_priv[t] += a[i];
}
} // end parallel
for (i = 0; i < nthreads; ++i) {
s += s_priv[i];
}
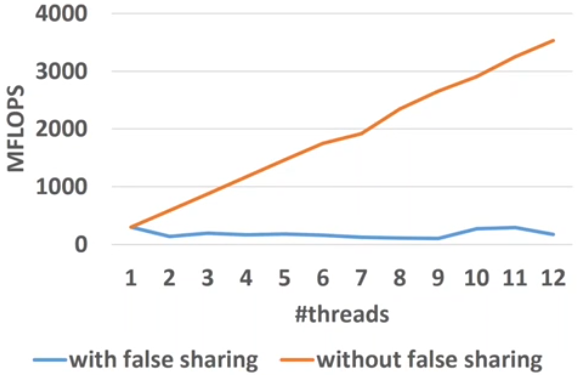
No performance benefit for more threads!
- Reason: false sharing of s_priv
- Solution: padding, so that only one variable per cache line is used.

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
/* Fasle sharing avoided */
// *8是为了保证不同线程不访问同一cacheline
double s_priv[nthreads * 8];
#pragma omp parallel num_threads(nthreads)
{
int t = omp_get_thread_num();
#pragame omp for
for (int i = 0; i < 99; ++i) {
s_priv[t * 8] += a[i];
}
} // end parallel
for (i = 0; i < nthreads; ++i) {
s += s_priv[i * 8];
}
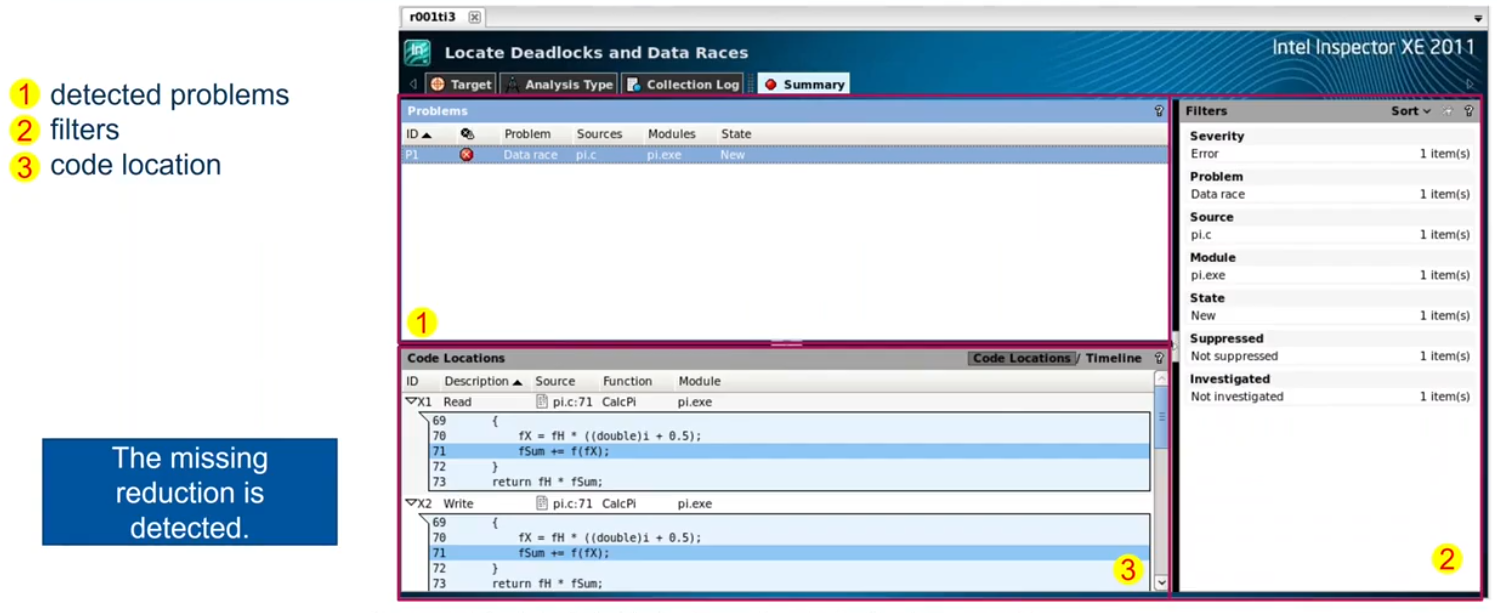
Race Condition
threads communicate by sharing variables, unintended sharing of data causes race conditions.
Data Race: a typical OpenMP programming error, when:
- two or more threads access the same memory location, and
- at least one of the accessed is a write, and
- the accesses are not protected by locks or critical regions, and
- the accesses are not synchronized, e.g. by a barrier.
Non-deterministic occurrence: e.g. the sequence of the execution of parallel loop iteratins is non-deterministic and may change from run to run.
In many cases private clauses, barriers or critical regions are missing.
Data races are hard to find using a traditional debugger.
- Use tools like Intel Inspector XE ThreadSanitizer, Archer.

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
/* Example of Calc Pi */
double f(dpuble x) {
return (4.0 / (1.0 + x * x));
}
double CalcPi(int n)
{
const double fH = 1.0 / (double) n;
double fSum = 0.0;
double fX;
int i;
#pragma omp parallel for private(fX, i, fSum)
for (i = 0; i < n; i++) {
fX = fH * ((double)i + 0.5);
fSum += f(fX);
}
return fH * fSum;
}
atomic directive
The statements inside the atomic must be one of the following forms:
1
2
3
4
5
6
7
x binop = expr
x++
++x
x--
--x
x is an lvalue of scalar type and binop is a non-overloaded built in operator.
1
2
3
4
5
6
7
8
9
#pragma omp parallel
{
double tmp, B;
B = DOIT();
tmp = big_ugly(B);
#pragma omp atomic
X += tmp;
}
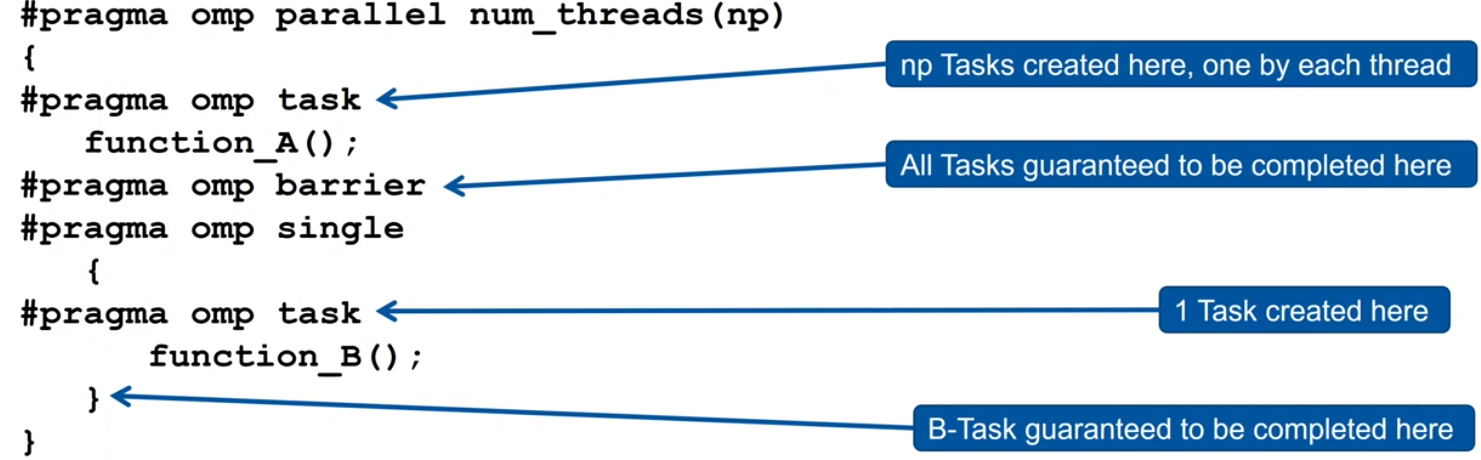
The barrier directive
All tasks created by any thread of the current Team are guaranteed to be completed at barrier exit.
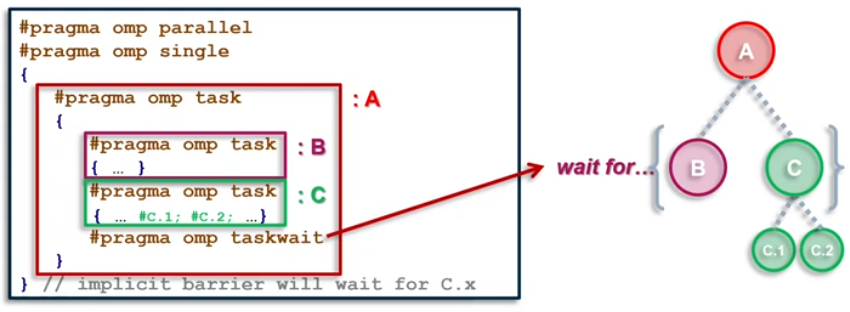
taskwait directive
A stand-alone directive
1
#pragma omp taskwait
wait on the completion of child tasks of the current task; just direct children, not all descendant task; includes an implicit task scheduling point(TSP)
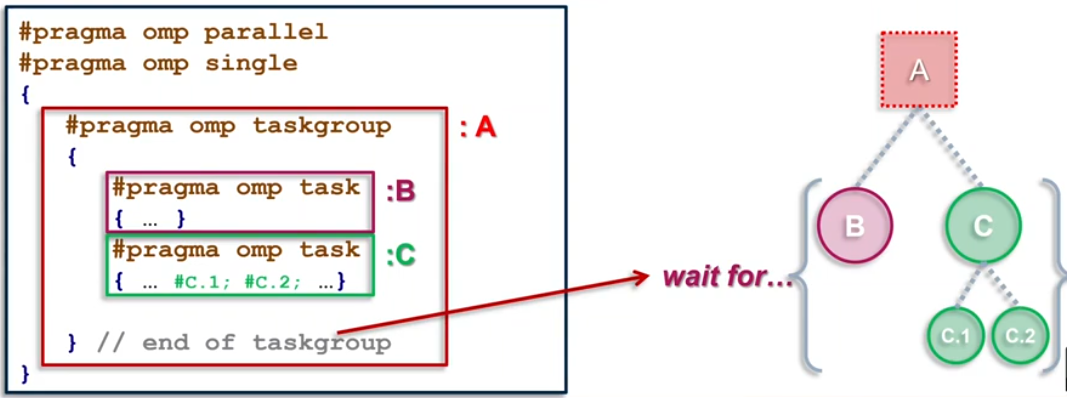
taskgroup directive
attached to a structured block; completion of all descendants of the current task; TSP at the end
1
2
#pragma omp taskgroup [clause[[,] clause]...]
{structured-block}
where clause(could only be): reduction(reduction-identifier:list-items)
Task Synchronization explained
Loops with Tasks
The taskloop Construct
Task generating construct: decompose a loop into chunks, create a task for each loop chunk
1
2
#pragma omp taskloop [clause[[,] clause]...]
{structured-for-loops}
clause is one of: 
Taskloop decomposition approaches

if none of previous clauses is present, the number of chunks and the number of iterations per chunk is implementation defined.
Additional considerations:
- The order of the creation of the loop tasks is unspecified
- Taskloop creates an implicit taskgroup region;
nogroup-> no implicit taskgroup region is created.
Task scheduling
Default: Tasks are tied to the thread that first executes them -> not neccessarily the creator.
Scheduling Constraints:
- Only the thread a task is tied to can execute it
- A task can only be suspended at task scheduling points: task creation, task finish, taskwait, barrier, taskyield
- If task is not suspended in a barrier, executing thread can only switch to a direct descendant of all tasks tied to hte thread.
Tasks created with the utied clause are never tied
- Resume at task scheduling points possibly by different thread
- But: More freedom to the implementation, e.g., load balancing.
Unsafe use of untied Tasks
problem: because untied tasks may migrate between threads at any point, thread-centric constructs can yield unexpected results.
Remember when using untied tasks:
- Avoid
threadprivatevariable - Avoid any use of thread-ids(e.g.,
omp_get_thread_num()) - Be careful with
critical regionand locks
Simple Solution
- Create a tied task region with
#pragma omp task if (0)
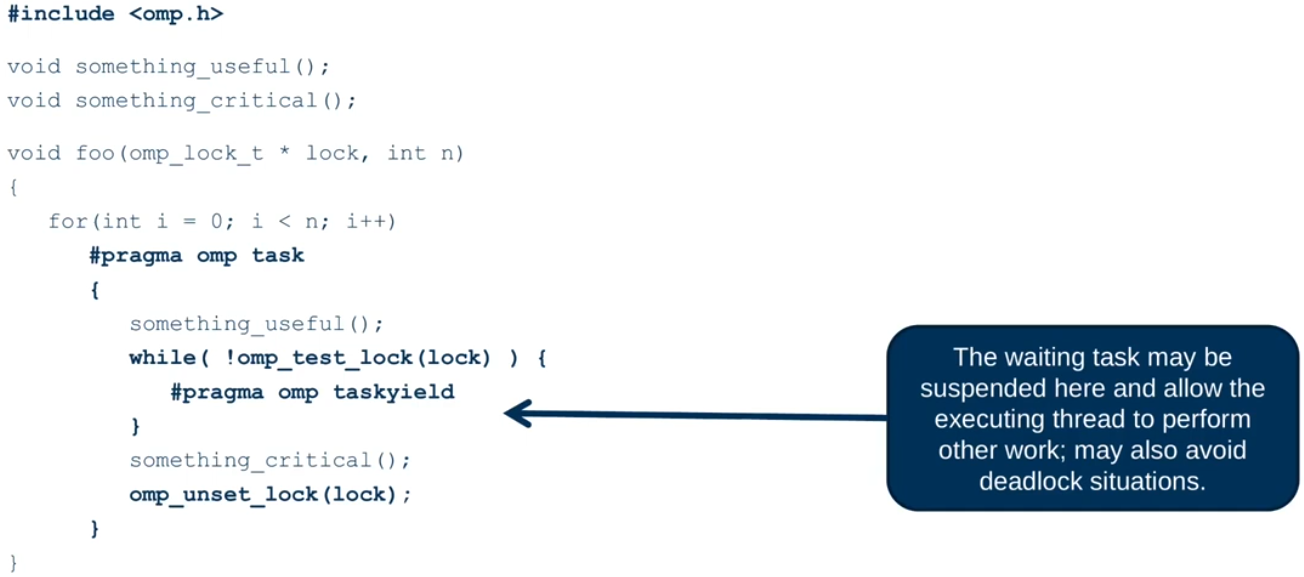
The taskyield Directive
The taskyield directive specifies that the current task can be suspended in favor of execution of a different- task.
- Hint to the runtime for optimization and/or deadlock prevention.
1
#pragma omp taskyield
Tasks and Dependencies
Task dependencies constrain execution order and times for tasks 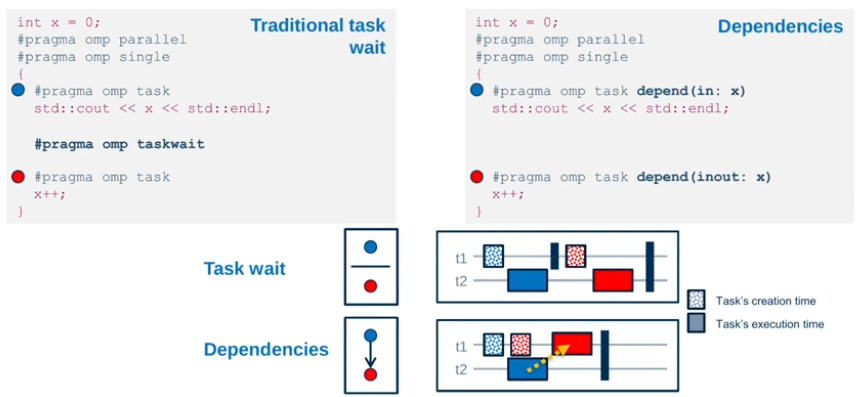
NUMA
Non-Uniform Memory Architecture 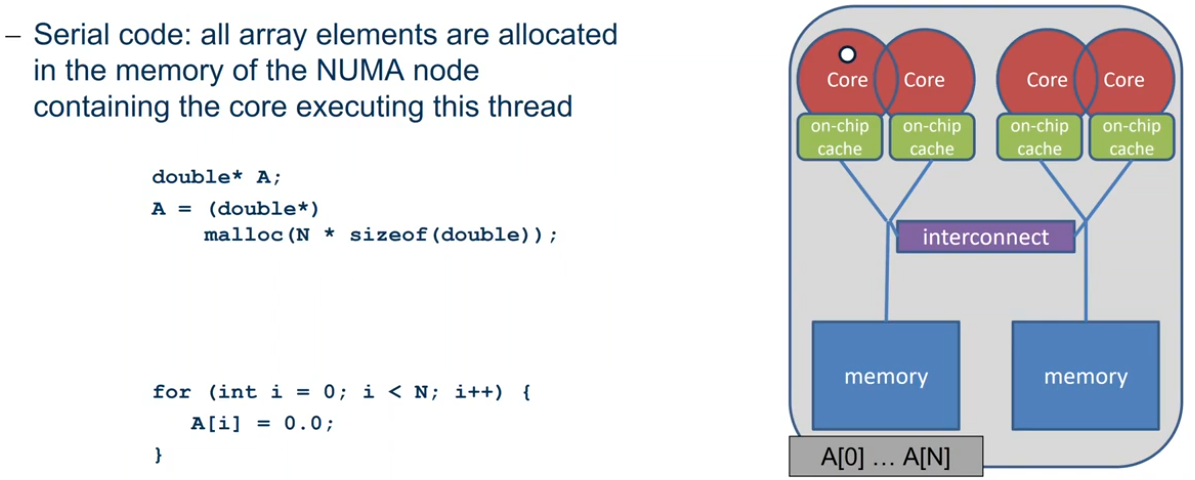

Get info on the system topology
Before you design a strategy for thread binding, you should have a basic understanding of the system topology. Please use one of the following options on a target machine
Intel MPI’s cpuinfo tool
- module switch openmpi intelmpi
- cpuinfo
- Delivers information about the number of sockets(=packages) and the mapping pf processor ids used by the operating system to cpu cores.
hwloc’s tool
- lstopo(command line:
hwloc-ls) - Display a graphical representation of the system topology, seperated into NUMA nodes, along with the mapping of processor ids used by the operating system to cpu cores and additional info on caches.
Decide for Binding Strategy
Select the right binding strategy depends not only on the topology, but also on the characteristics of your application.
putting threads far apart, i.e. on different sockets
- May improve the aggregated memory bandwidth available to your application
- May improve the combined cache size available to your application
- May decrease performance of synchronization constructs
putting threads close together, i.e. on two adjacent cores which possibly shared some caches
- May improve performance of synchronization constructs
- May decrease the available memory bandwidth and cache size
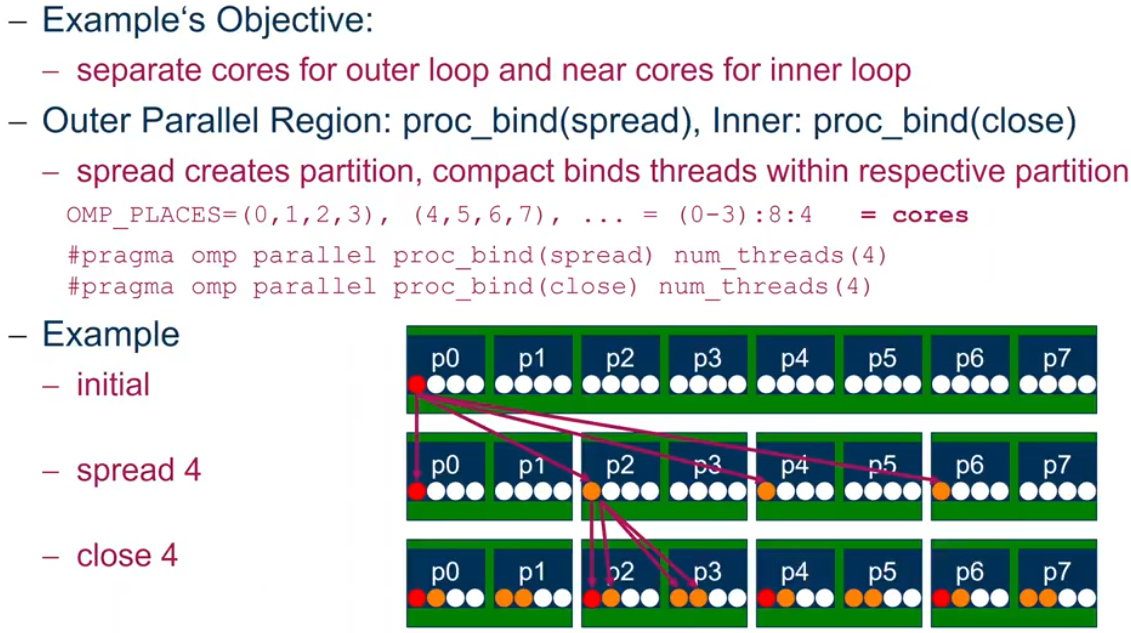
OpenMP 4.0: Places + Binding Policies(1/2)
Define OpenMP Places
- Set of OpenMP threads running on one or more processors
- can be defined by the user, i.e.
OMP_PLACES=cores
Define a set of OpenMP Thread Affinity Policies
- SPREAD: spread OpenMP threads evenly among the places
- CLOSE: pack OpenMP threads near master thread
- MASTER: collocate OpenMP thread with master thread
Goals
- user has a way to specify where to execute OpenMP threads for
- locality between OpenMP threads/less false sharing/memory bandwidth
Abstract names for OMP_PLACES:
- threads: each place corresponds to a single hardware thread on the target machine.
- cores: each place corresponds to a single core (having one or more hardware threads) on the target machine.
- sockets: each place corresponds to a single socket(consisting of one or more cores) on the target machine.
- ll_caches(5.1): each place corresponds to a set of cores that share the last level cache.
- numa_domains(5.1): each place corresponds to a set of cores for which their closest memory is: the same memory; and at a similar distance from the cores.
OpenMP 4.0: Places + Binding Policies(2/2)